В данной статье описана начальная установка и настройка пакета Pacemaker на сервер под управлением CentOS7
Задача: настроить Pacemaker на автоматическое переключение Master\Slave
Дано:
node1 CentOS7
node2 CentOS7
Решение:
Установка
Устанавливаем пакеты на каждую из нод будущего кластера.
|
1 2 3 |
yum -y install resource-agents pacemaker pcs fence-agents-all psmisc policycoreutils-python corosync |
Задать пароль на пользователя, под которым будет работать сервис и выполняться синхронизация
|
1 2 3 |
passwd hacluster |
Запустим службу и добавим в автозагрузку
|
1 2 3 4 5 |
systemctl enable pcsd systemctl enable corosync systemctl enable pacemaker |
Настройка
Добавим имена хостов в файл /etc/hosts
|
1 2 3 4 |
100.201.203.51 node1 100.201.203.52 node2 |
Запуск
Открываем порты
|
1 2 3 4 |
firewall-cmd --permanent --add-service=high-availability firewall-cmd --add-service=high-availability |
Данную процедуру выполняем на каждом из серверов.
Первым делом, необходимо авторизоваться на серверах следующей командой
|
1 2 3 4 5 6 7 |
#pcs cluster auth node1 node2 -u hacluster Password: node2: Authorized node1: Authorized |
Создаем кластер
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
pcs cluster setup --force --name CLUSETR node1 node2 Destroying cluster on nodes: node1, node2... node1: Stopping Cluster (pacemaker)... node2: Stopping Cluster (pacemaker)... node2: Successfully destroyed cluster node1: Successfully destroyed cluster Sending 'pacemaker_remote authkey' to 'node1', 'node2' node1: successful distribution of the file 'pacemaker_remote authkey' node2: successful distribution of the file 'pacemaker_remote authkey' Sending cluster config files to the nodes... node1: Succeeded node2: Succeeded Synchronizing pcsd certificates on nodes node1, node2... node2: Success node1: Success Restarting pcsd on the nodes in order to reload the certificates... node2: Success node1: Success |
Разрешаем автозапуск и запускаем созданный кластер pcs cluster enable —all и pcs cluster start —all:
|
1 2 3 4 5 6 7 8 9 10 |
pcs cluster enable --all node1: Cluster Enabled node2: Cluster Enabled pcs cluster start --all node1: Starting Cluster (corosync)... node2: Starting Cluster (corosync)... node2: Starting Cluster (pacemaker)... node1: Starting Cluster (pacemaker)... |
При использовании 2-х нод (как в данном примере) отключаем stonith (нужен для «добивания» серверов, которые не смогли полностью завершить рабочие процессы) и кворум. STONITH (Shoot The Other Node In The Head) или Shoot является дополнительной защитой Pacemaker. При выполнении команды pcs status вы увидите предупреждение в выходных данных о том, что никакие устройства STONITH не настроены, и STONITH не отключен. Если вы используете данное решение в продакшене, то лучше включить STONITH. Так как даная система будет работать в DMZ, мы отключаем STONITH. Наличие кворума означает, что в кластере должно быть не менее 3-х узлов. Причем, необязательно все три узла должны быть с СУБД, достаточно на двух узлах иметь Мастер и Реплику, а третий узел выступает в роли «голосующего».
Наличие устройств фенсинга на узлах с СУБД. При возникновении сбоя устройства «фенсинга» изолируют сбойнувший узел – посылают команду на выключение питания или перезагрузку (poweroff или hard-reset). Выполняем на обоих нодах
|
1 2 3 4 |
pcs property set stonith-enabled=false pcs property set no-quorum-policy=ignore |
Если получаем ошибку
|
1 2 3 4 |
Error: unable to get cib Error: unable to get cib |
То скорее всего не запущены сервисы pcs cluster enable —all и pcs cluster start —all или не установлен пакет fence-agents-all
Что такое кворум? Говорят, что кластер имеет кворум при достаточном количестве «живых» узлов кластера. Достаточность количества «живых» узлов определяется по формуле ниже
|
1 2 3 |
n > N/2 |
где n – количество живых узлов, N – общее количество узлов в кластере.
Как видно из простой формулы, кластер с кворумом – это когда количество «живых» узлов, больше половины общего количества узлов в кластере. Как вы, наверное, понимаете, в кластере, состоящем из двух узлов, при сбое на одном из 2-х узлов не будет кворума. По умолчанию, если нет кворума, Pacemaker останавливает ресурсы. Чтобы этого избежать, нужно при настройке Pacemaker указать ему, чтобы наличие или отсутствие кворума не учитывалось. Делается это с помощью опции no-quorum-policy=ignore.
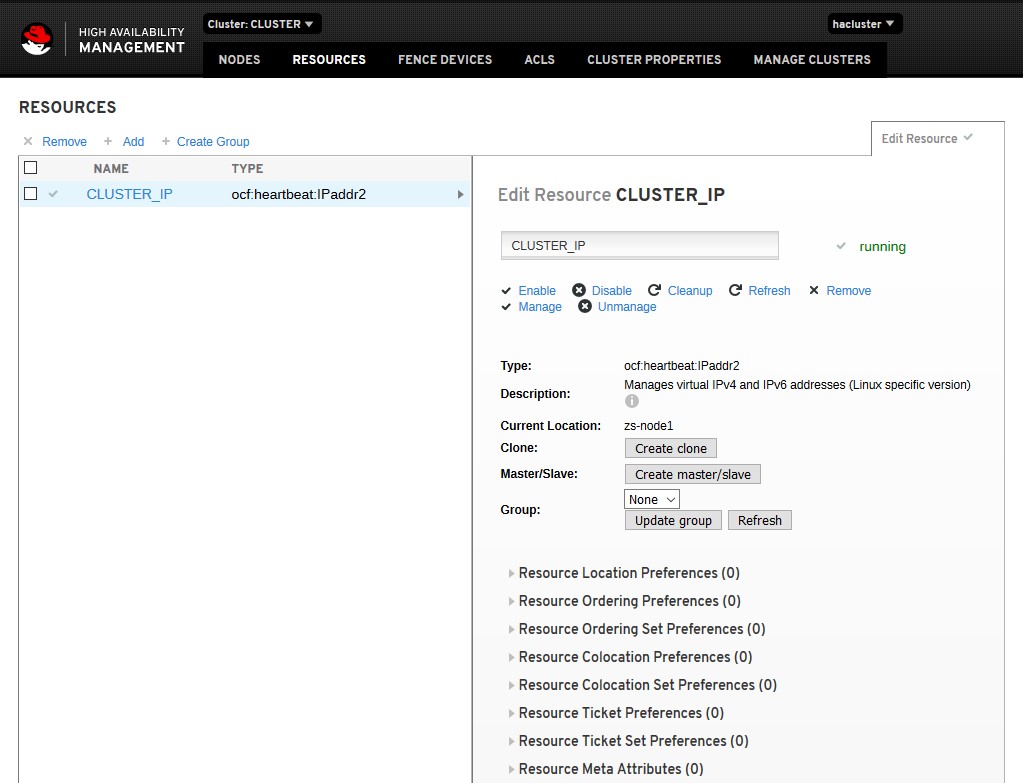
Рассмотрим самый распространенный вариант использования Pacemaker. Он заключается в использовании виртуального IP-адреса, который будет назначаться активному узлу кластера.
Для этого создаем ресурс командой:
|
1 2 3 |
pcs resource create CLUSTER_IP ocf:heartbeat:IPaddr2 ip=100.201.203.50 cidr_netmask=24 op monitor interval=60s |
,где CLUSTER_IP — название ресурса (может быть любым);
ip=100.201.203.50 — виртуальный IP, который будет назначен кластеру;
cidr_netmask=24 — префикс сети (соответствует маске 255.255.255.0);
op monitor interval=60s — критическое время простоя, которое будет означать недоступность узла
Виды сбоев
Сбой по питанию на текущем мастере или на реплике
Сбой питания, когда пропадает питание и сервер выключается. Это может быть как Мастер, так и одна из Реплик.
Сбой процесса
Сбой основного процесса – система может завершить аварийно процесс postgres по разным причинам, например, нехватка памяти, либо недостаточное количество файловых дескрипторов, либо превышено максимальное число открытых файлов.
Потеря сетевой связности между каким-либо из узлов и остальными узлами
Это сетевая недоступность какого-либо узла. Например, её причиной может быть выход из строя сетевой карты, либо порта коммутатора.
Сбой процесса Pacemaker/Corosync
Сбой процесса Corosync/pacemaker
Работа в командной строке PCS
Посмотреть параметры
|
1 2 3 |
pcs property list |
Посмотреть состояние кластера
|
1 2 3 |
pcs status |
Отключить все ресурсы кластера
|
1 2 3 |
pcs cluster disable --all |
Ресурсы имеют множество атрибутов, которые хранятся в конфигурационном XML-файле Pacemaker’а. Наиболее интересные из них: priority, resource-stickiness, migration-threshold, failure-timeout, multiple-active.
Рассмотрим их более подробно.
Атрибут priority — приоритет ресурса, который учитывается, если узел исчерпал лимит по количеству активных ресурсов (по умолчанию 0). Если узлы кластера не одинаковы по производительности или доступности, то можно увеличить приоритет одного из узлов, чтобы он был активным всегда, когда работает.
Атрибут resource-stickiness — липкость ресурса (по умолчанию 0). Липкость (stickiness) указывает на то, насколько ресурс «хочет» оставаться там, где он есть сейчас. Например, после сбоя узла его ресурсы переходят на другие узлы (точнее — стартуют на других узлах), а после восстановления работоспособности сбойного узла, ресурсы могут вернуться к нему или не вернуться, и это поведение как раз и описывается параметром липкость.
Другими словами, липкость показывает, насколько желательно или не желательно, чтобы ресурс вернулся на восстановленный после сбоя узел.
Поскольку по умолчанию липкость всех ресурсов 0, то Pacemaker сам располагает ресурсы на узлах «оптимально» на свое усмотрение.
Но это не всегда может быть оптимально с точки зрения администратора. Например, в случае, когда в отказоустойчивом кластере узлы имеют неодинаковую производительность, администратор захочет запускать сервисы на узле с большей производительностью.
Также Pacemaker позволяет задавать разную липкость ресурса в зависимости от времени суток и дня недели, что позволяет, например, обеспечить переход ресурса на исходный узел в нерабочее время.
Атрибут migration-threshold — сколько отказов должно произойти, чтобы Pacemaker решил, что узел непригоден для данного ресурса и перенёс (мигрировал) его на другой узел. По умолчанию также этот параметр равен 0, т. е. при любом количестве отказов автоматического переноса ресурсов не будет происходить.
Но, с точки зрения отказоустойчивости, правильно выставить этот параметр в 1, чтобы при первом же сбое Pacemaker перемещал ресурс на другой узел.
Атрибут failure-timeout — количество секунд после сбоя, до истечения которых Pacemaker считает, что отказа не произошло, и не предпринимает ничего, в частности, не перемещает ресурсы. По умолчанию, равен 0.
Атрибут multiple-active – дает указание Pacemaker, что делать с ресурсом, если он оказался запущен более чем на одном узле. Может принимать следующие значения:
block — установить опцию unmanaged, то есть деактивировать
stop_only — остановить на всех узлах
stop_start — остановить на всех узлах и запустить только на одном (значение по-умолчанию).
По умолчанию, кластер не следит после запуска, жив ли ресурс. Чтобы включить отслеживание ресурса, нужно при создании ресурса добавить операцию monitor, тогда кластер будет следить за состоянием ресурса. Параметр interval этой операции – интервал, с каким делать проверку.
При возникновении отказа на основном узле, Pacemaker «перемещает» ресурсы на другой узел (на самом деле, Pacemaker останавливает ресурсы на сбойнувшем узле и запускает ресурсы на другом). Процесс «перемещения» ресурсов на другой узел происходит быстро и незаметно для конечного клиента.
Ресурсы можно объединять в группы — списки ресурсов, которые должны запускаться в определенном порядке, останавливаться в обратном порядке и исполняться на одном узле.Все ресурсы группы запускаются на одном узле и запускаются последовательно, согласно порядку в группе. Но нужно учитывать, что при сбое одного из ресурсов группы, вся группа переместится на другой узел.
При выключении какого-либо ресурса группы, все последующие ресурсы группы тоже выключатся. Например, ресурс PostgreSQL, имеющий тип pgsql, и ресурс Virtual-IP, имеющий тип IPaddr2, могут быть объединены в группу.
Остановить все ноды
|
1 2 3 |
pcs cluster stop --all |
Посмотреть состояние ресурсов
|
1 2 3 |
pcs status resources |
Изменить активную ноду
|
1 2 3 |
pcs resource move CLUSTER_IP zs-node1 |
Удаление ноды
|
1 2 3 |
pcs cluster node remove node_name |
Очистка счетчиков сбоев
|
1 2 3 |
pcs resource cleanup |
Пример создания ресурса PostgreSQL типа pgsql в кластере из трех узлов pgsql01, pgsql02, pgsql03
|
1 2 3 4 5 6 |
pcs resource create PostgreSQL pgsql pgctl="/usr/pgsql-9.6/bin/pg_ctl" \psql="/usr/pgsql-9.6/bin/psql" pgdata="/var/lib/pgsql/9.6/data/" \rep_mode="sync" node_list=" pgsql01 pgsql02 pgsql03" restore_command="cp /var/lib/pgsql/9.6/pg_archive/%f %p" \primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5" master_ip="10.3.3.3" restart_on_promote='false' |
Работа в командном интерпретаторе CRM
Данная утилита имеет собственный SHELL, в котором довольно удобно работать. Из настроек данного интерпретатора можно отметить назначение редактора, в котором вы привыкли работать, например nano или mcedit.
|
1 2 3 4 5 |
crm options editor vim crm opti edi mcedit crm conf edit |
Посмотреть конфигурацию
|
1 2 3 |
crm configure show |
Сохранение конфигурации
|
1 2 3 |
crm configure save _BACKUP_PATH_ |
Восстановление конфигурации
|
1 2 3 |
crm configure load replace _BACKUP_PATH |
Дополнения
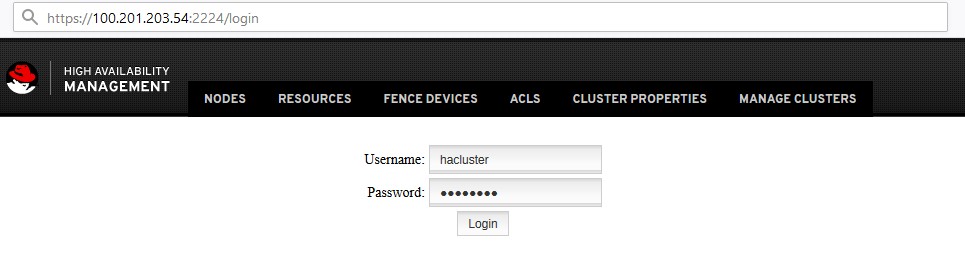
Администрирование через WEB
Каждая из нод слушает порт 2224, которая позволяет подключиться и посмотреть, а так же изменить конфигурацию
Например https://100.201.203.54:2224
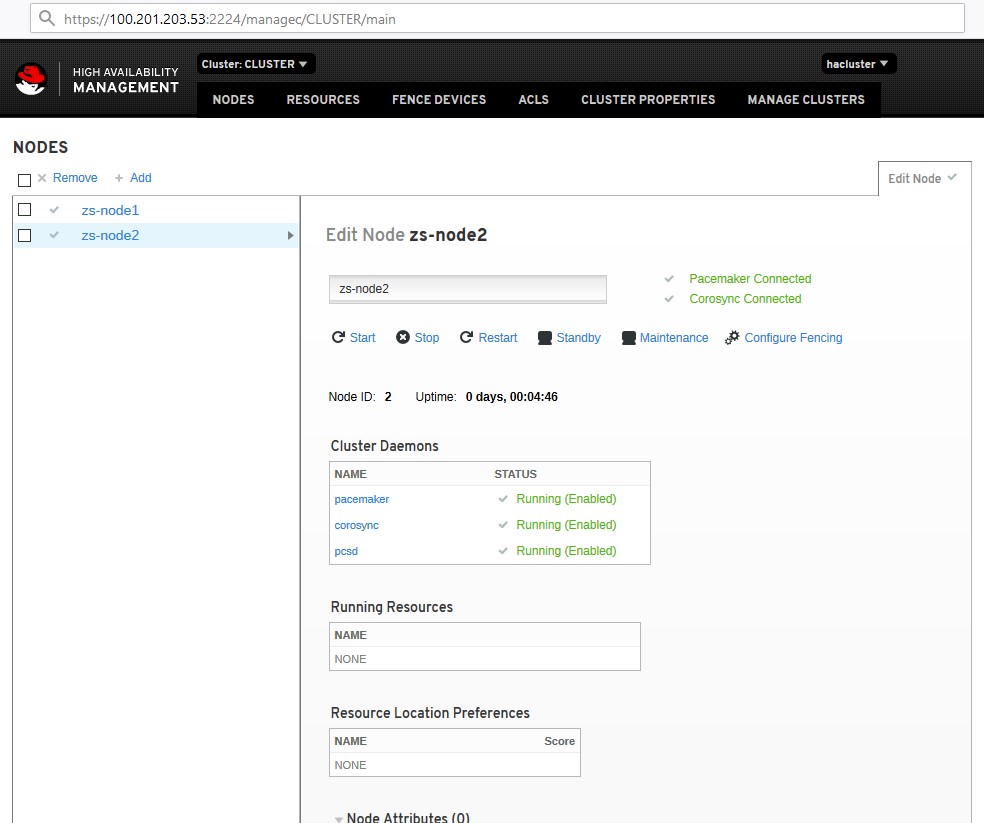
 Так же доступен и IP кластера.
Так же доступен и IP кластера.
Установка CRM
|
1 2 3 4 |
[kost@node1 ~]# crm-bash: crm: command not found |
|
1 2 3 4 5 |
cd /etc/yum.repos.d/ wget http://download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-7/network:ha-clustering:Stable.repo yum install crmsh |
Дополнительно
Хорошие стать по данной тем