Казалось бы полезный механизм — дедупликация, но возникла ситуация, когда размер хранилища дедуплицированных данных стал весить больше, чем сами данные! Глубина архива — неделя. Возможно не хватает именно задания очистки от данных, которые более не актуальны, так как архивы, по большому счету, имеют однородную структуру и могут быть отлично дедуплицированны. Но дело не только в этом. Необходимо выяснить, как в этом случае расходуется место. После отключения дедупликации, место так и осталось занятым. Что же можно сделать
Все команды выполняются в PowerShell от имени администратора. Первое, что я сделал, это выполнил выполнил чистку массива
Start-DedupJob -Volume D: —Type GarbageCollection
После чего на массиве было высвобождено около 9 Тб, о чем свидетельствуют данные мониторинга. Процесс занял около 10 часов
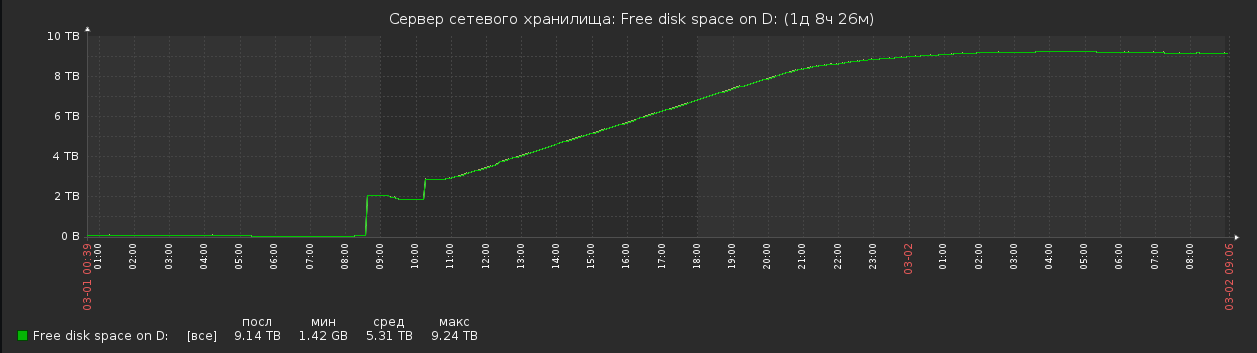
Далее запустил процесс восстановления данных, интересно что получиться, были в хранилище нужные данные или нет, выясниться после завершения процесса
|
1 2 3 |
Start-DedupJob Optimization d: |
В случае переполнения диска, при использовании задания обратному дедупликации (Start-DedupJob -Volume D: -Type Unoptimization) , необходимо выполнить следующее
Остановить процесс восстановления
|
1 2 3 |
<span class="hljs-keyword">Stop</span>-DedupJob -Volume <span class="hljs-keyword">D</span>: |
Так как данная операция автоматически выключает дедупликацию для тома снова включим ее:
|
1 2 3 |
Enable-DedupVolume -Volume D: |
И запустить уборку мусора:
|
1 2 3 |
Start-DedupJob -Volume D: -Type GarbageCollection |
Посмотреть задачи дедупликации следующей командой
|
1 2 3 |
<span class="hljs-keyword">Get</span>-DedupJob |
![]()
Настройку параметров дедупликации думаю будет разумно выполнить следующим образом
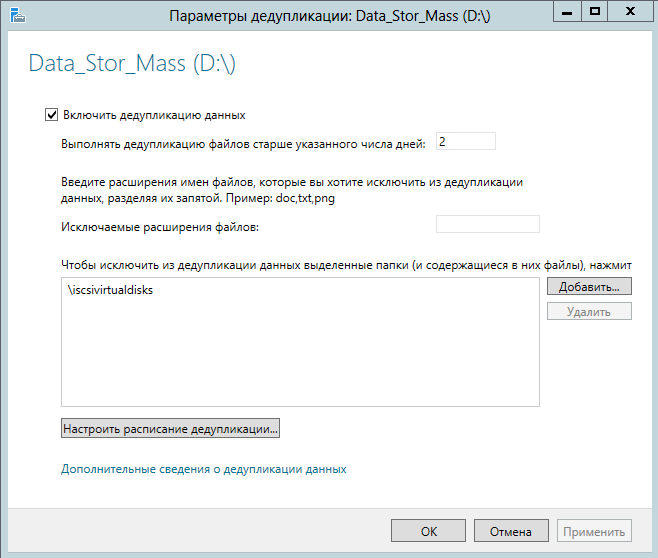 Настройка планировщика
Настройка планировщика
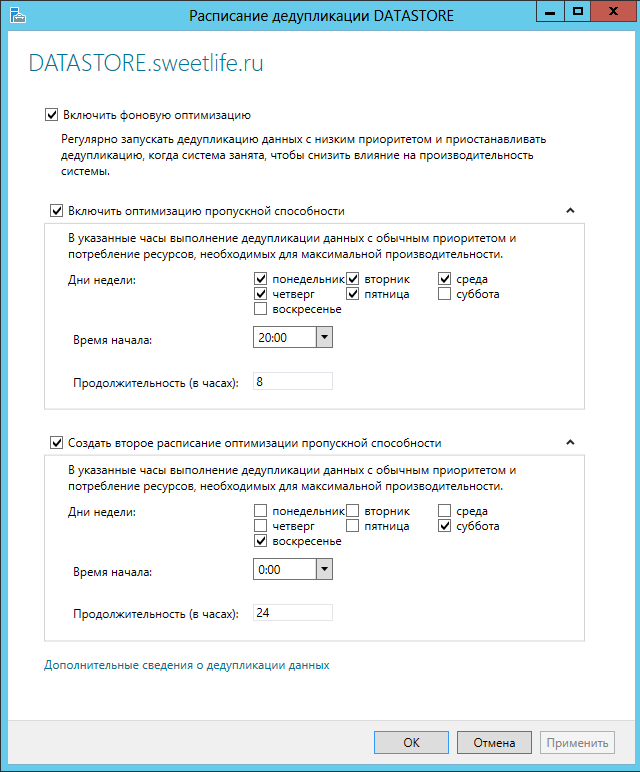 Немного информации об экономии и каталоге с дедуплицированными данными до очистки от мусока
Немного информации об экономии и каталоге с дедуплицированными данными до очистки от мусока
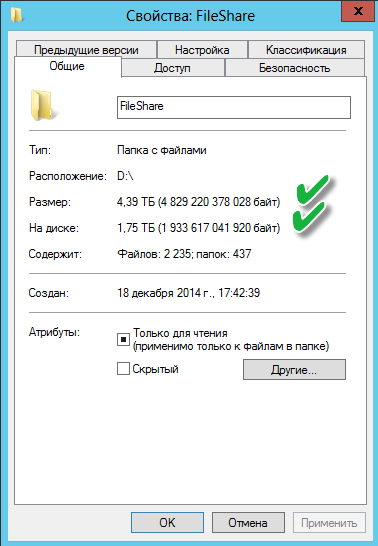
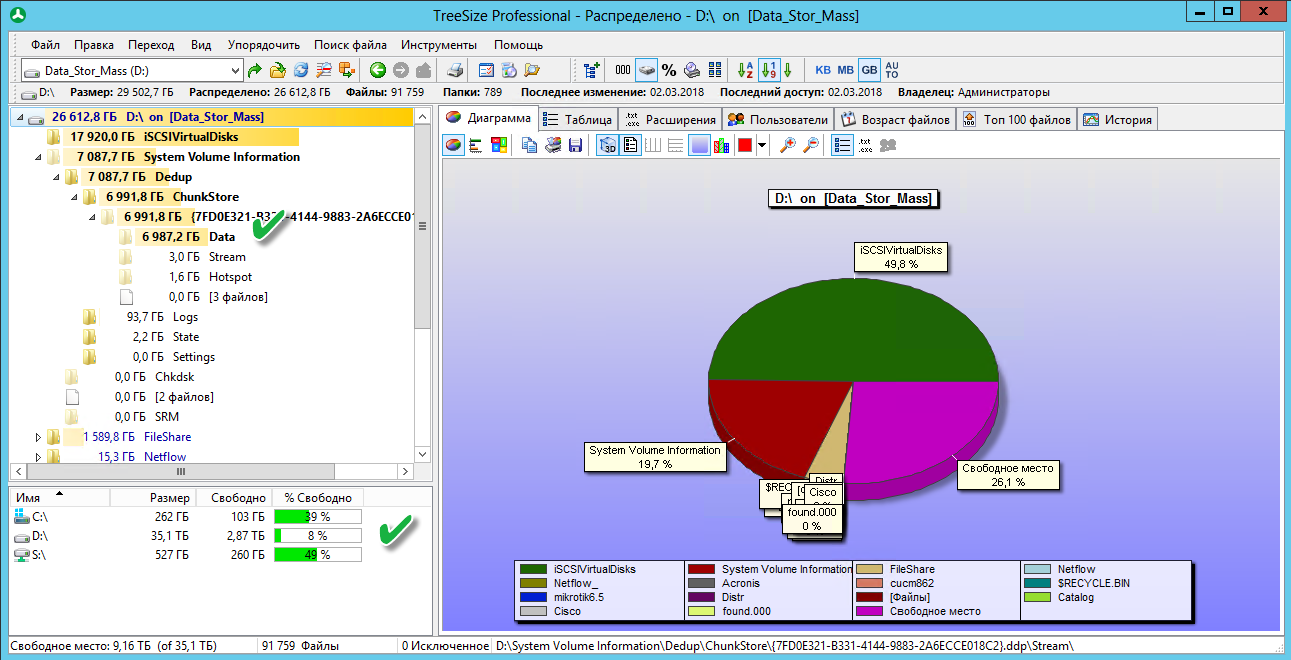
Результат проделанной работы
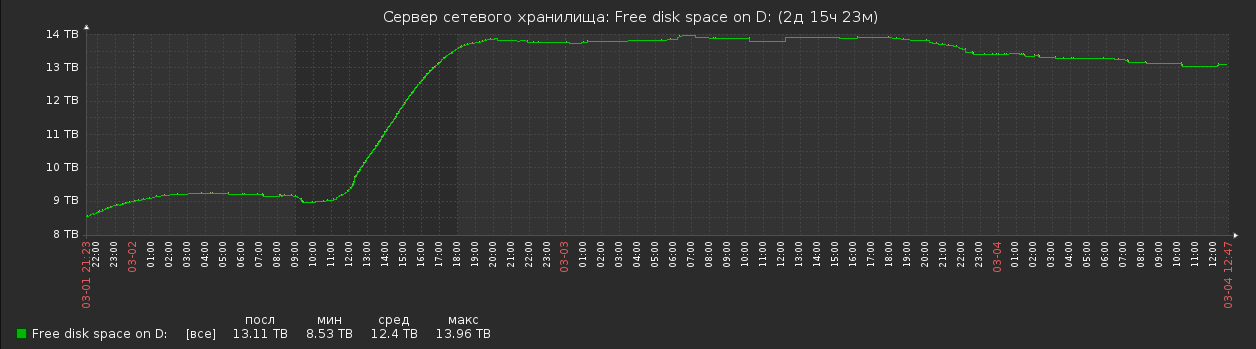
Дополнительную информацию можно посмотреть на сайте interface31. Спасибо автору не только за решение, но и за теорию.